|
Ziteng Cui (崔 子藤)
I am a specially appointed assistant professor (特任助教) at the University of Tokyo, affiliated with the MIL Lab at RCAST. I received my Ph.D. from same lab in the University of Tokyo (2025.06), M.S. from Shanghai Jiao Tong University, and B.S. from Harbin Institute of Technology.
I mainly work on Physics-based Vision & Computational Photography & 3D Computer Vision. My favorite things are DOTA2, hiking, anime (FATE, JOJO, One Piece, HunterxHunter ...) and Britpop.
My research goal is to integrate physical intrinsic knowledge into real-world downstream applications (e.g., perception, 3D vision, robotics). I'm always open to academic collaborations, feel free to reach out.
News: I will join HKUST(GZ) AI Thrust as an Assistant Professor, and establish Robust AI in the Wild Lab, I will be recruiting PhD students, Master students, visiting students/RAs for 2027! Feel free to email me (cui [at] mi.t.u-tokyo.ac.jp) if you are interested.
我将加入香港科技大学(广州)人工智能学域担任助理教授,并且组建Robust AI in the Wild Lab,目前正在招募2027年入学的博士生硕士生以及访问学生/科研助理!如果你对我的研究方向感兴趣,欢迎随时发邮件聊聊 🙌 (cui [at] mi.t.u-tokyo.ac.jp)
Email /
Google Scholar /
Github /
Twitter /
LinkedIn /
Lab Page
|

|
|
News
● 2026.06 I will give an invited talk at CVPR 2026 AIGENS workshop 🎙️🎙️
● 2026.05 One first author paper RAW-Adapter (Extended version) has been accepted by TPAMI 2026 ☀️☀️
● 2026.03 I received the Dean’s Award from the Graduate School of Engineering (工学系研究科長賞), UTokyo 💐💐
● 2026.02 Two papers (including 1 Finding paper) have been accepted by CVPR 2026, congrats to the team ☀️☀️
● 2026.02 Co-host the 3D Restoration and Reconstruction (3DRR) challenge and Efficient Super-Resolution Challenge in CVPR NTIRE workshop 📷📷
● 2025.11 One paper LHSI has been accepted by WACV 2026, congrats to the team ☀️☀️
● 2025.09 Two papers Dr. RAW and I2-NeRF have been accepted by NeurIPS 2025, congrats to the team ☀️☀️
● 2025.09 I have been selected to the Doctoral Consortium at BMVC 2025, and will give an invited talk at BMVC 2025 smart camera workshop 🎙️🎙️
● 2025.08 One paper AR-Talk has been accepted by Siggraph Asia 2025, congrats to the team ☀️☀️
● 2025.06 I successfully defended my Ph.D. dissertation, Dr. Cui now 💐💐
● 2025.04 I have been selected to the Doctoral Consortium at CVPR 2025 ☀️☀️
● 2025.02 One first author paper Luminance-GS has been accepted by CVPR 2025 ☀️☀️
● 2024.08 One first author paper IAC has been accepted by BMVC 2024 ☀️☀️
● 2024.07 One first author paper RAW-Adapter has been accepted by ECCV 2024 ☀️☀️
● 2023.12 One first author paper Aleth-NeRF has been accepted by AAAI 2024 ☀️☀️
● ... ...
|
|
Publications
(show selected
/ show all)
I'm now interested in the physics modeling in 3D computer vision and camera design, I especially interested in implicit modeling. "*" means authors contribute equally. "#" means corresponding author.
|

|
RealX3D: A Physically-Degraded 3D Benchmark for Multi-view Visual Restoration and Reconstruction
Shuhong Liu*, Chenyu Bao*, Ziteng Cui, Yun Liu, Xuangeng Chu, Lin Gu, Marcos V. Conde, Ryo Umagami, Tomohiro Hashimoto, Zijian Hu, Tianhan Xu, Yuan Gan, Yusuke Kurose, Tatsuya Harada.
Arxiv, 2026 [challenge website] [github]
arxiv /
bibtex
|
|
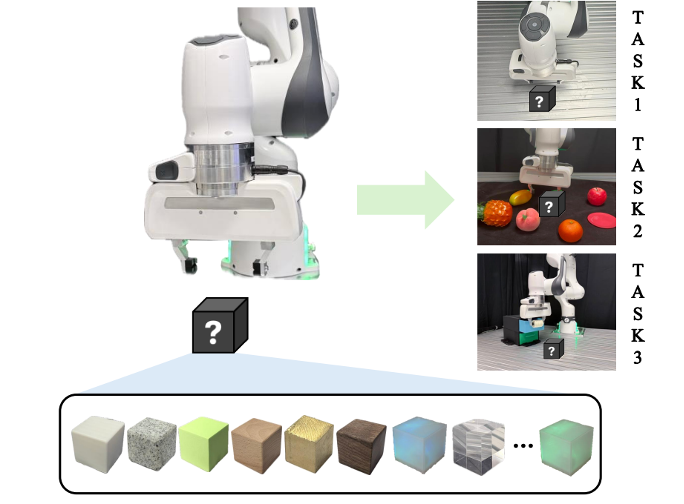
M3APolicy: Mutable Material Manipulation Augmentation Policy through Photometric Re-rendering
Jiayi Li, Yuxan Hu, Haoran Geng, Xiangyu Chen, Chuhao Zhou, Ziteng Cui, Jianfei Yang.
CVPR, 2026 Findings
arxiv /
bibtex
|

|
MERIT: Multi-domain Efficient RAW Image Translation
Wenjun Huang, Shenghao Fu, Yian Jin, Yang Ni, Ziteng Cui, Hanning Chen, Yirui He, Yezi Liu, Sanggeon Yun, SungHeon Jeong, Ryozo Masukawa, William Youngwoo Chung, Mohsen Imani.
CVPR, 2026
arxiv /
bibtex
|
|
|
Perception-Inspired Color Space Design for Photo White Balance Editing
Yang Cheng, Ziteng Cui#, Lin Gu, Shenghan Su, Zenghui Zhang.
WACV, 2026 [github]
arxiv /
bibtex
|
|
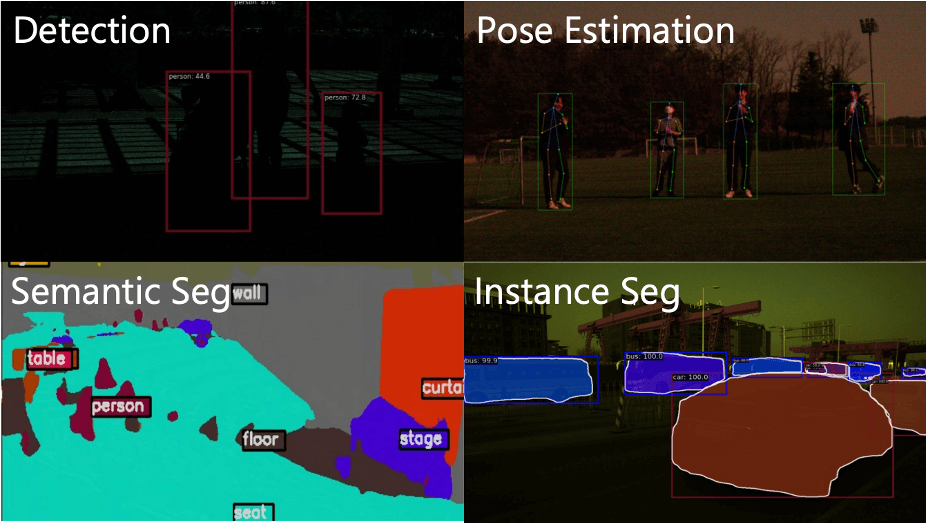
Dr. RAW: Towards General High-Level Vision from RAW with Efficient Task Conditioning
Wenjun Huang*, Ziteng Cui*, Yinqiang Zheng, Yirui He, Tatsuya Harada, Mohsen Imani.
NeurIPS, 2025
arxiv /
bibtex
|
|
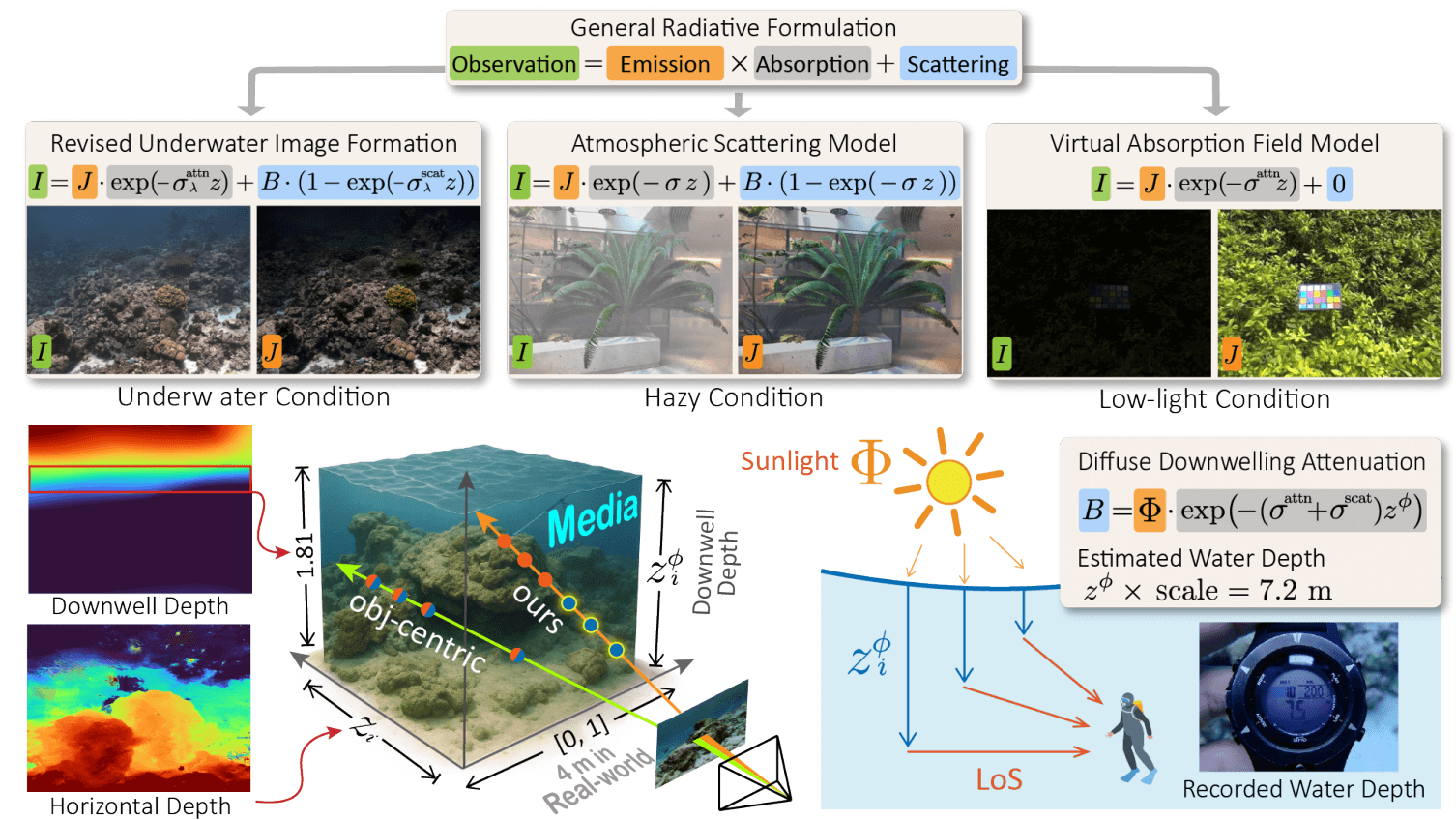
I2-NeRF: Learning Neural Radiance Fields Under Physically-Grounded Media Interactions
Shuhong Liu, Lin Gu, Ziteng Cui, Xuangeng Chu, Tatsuya Harada.
NeurIPS, 2025 [github]
website /
arxiv /
bibtex
|
|
|
Luminance-GS: Adapting 3D Gaussian Splatting to Challenging Lighting Conditions with View-Adaptive Curve Adjustment
Ziteng Cui#, Xuangeng Chu, Tatsuya Harada.
CVPR, 2025 [github] 
website /
arxiv /
bibtex /
poster
|
|
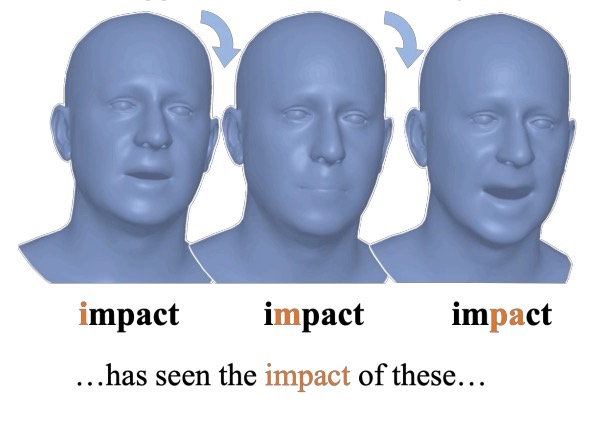
ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model
Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, Tatsuya Harada.
SIGGRAPH ASIA, 2025 [github] 
website /
arxiv /
bibtex
|
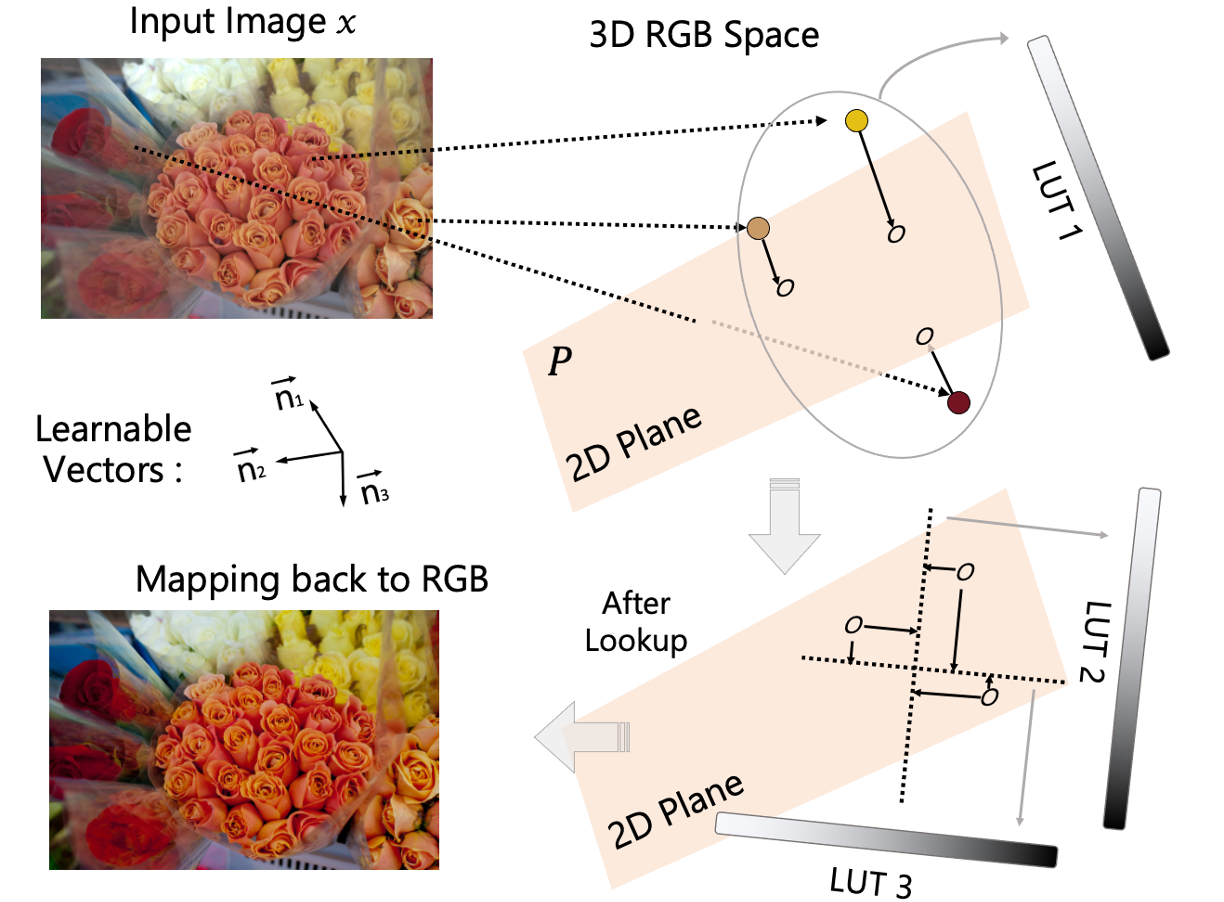
|
Discovering an Image-Adaptive Coordinate System for Photography Processing
Ziteng Cui, Lin Gu, Tatsuya Harada.
BMVC, 2024
arxiv /
bibtex
|
|
|
RAW-Adapter: Adapting Pre-trained Visual Model to Camera RAW Images
Ziteng Cui#, Tatsuya Harada.
ECCV, 2024 [github] 
RAW-Adapter: Adapting Pre-trained Visual Model to Camera RAW Images and A Benchmark
Ziteng Cui, Jianfei Yang, Tatsuya Harada.
TPAMI, 2026
website /
arxiv /
journal version /
bibtex /
poster
|
|
|
Aleth-NeRF: Illumination Adaptive NeRF with Concealing Field Assumption
Ziteng Cui,
Lin Gu, Xiao Sun, Xianzheng Ma, Yu Qiao, Tatsuya Harada.
AAAI, 2024 [github] 
website /
arxiv /
arxiv (old version) /
bibtex /
poster
|

|
Monodetr: Depth-guided transformer for monocular 3d object detection
Renrui Zhang, Han Qiu, Tai Wang, Ziyu Guo, Ziteng Cui, Yu Qiao, Hongsheng Li, Peng Gao
ICCV, 2023 [github] 
arxiv /
bibtex /
code /
poster
|
|
|
You Only Need 90K Parameters to Adapt Light: A Light Weight Transformer for Image Enhancement and Exposure Correction
Ziteng Cui,
Kunchang Li,
Lin Gu, Shenghan Su, Peng Gao, Zhengkai Jiang, Yu Qiao, Tatsuya Harada.
BMVC, 2022 [github]  (✨ Most Cited in BMVC 2022) (✨ Most Cited in BMVC 2022)
arxiv /
bibtex /
demo /
poster
|

|
Exploring Resolution and Degradation Clues as Self-supervised Signal for Low Quality Object Detection
Ziteng Cui,
Yingying Zhu,
Lin Gu, Guo-Jun Qi, Xiaoxiao Li, Renrui Zhang, Zenghui Zhang, Tatsuya Harada.
ECCV, 2022 [github] 
arxiv /
bibtex /
poster
|

|
Multitask AET with Orthogonal Tangent Regularity for Dark Object Detection
Ziteng Cui,
Guo-Jun Qi,
Lin Gu, Shaodi You, Zenghui Zhang, Tatsuya Harada.
ICCV, 2021 [github] 
arxiv /
bibtex /
poster
|

|
Dean’s Award, Graduate School of Engineering, The University of Tokyo, 2026
BMVC 2025 Doctoral Consortium, 2025
CVPR 2025 Doctoral Consortium, 2025
ICCV 2025 Outstanding Reviewer, 2025
CVPR 2025 Outstanding Reviewer, 2025
Shanghai Jiao Tong University Excellent Graduate Student, 2022
Ministry of Education of P.R. China National Scholarship, 2021
|
|
Affiliations & Experiences
|

|
Workshop Organizer: CVPR 2026 NTIRE 3DRR Challenge, CVPR 2026 NTIRE Efficient SR Challenge, BMVC 2025 Smart Camera Workshop
Technical Program Committee: Pacific Graphics 2026
Reviewer: CVPR, ICCV, ECCV, TPAMI, IJCV, TOG, TVCG, ICLR, ICML, NIPS, ACM MM, AISTATS, BMVC, ACCV, WACV, AAAI, Siggraph, Siggraph Asia, Eurographics, Pacific Graphics, TNNLS, TCSVT, ...
|
|







